Web Scrape With Multi-Threaded File Downloads Using Python
](https://cdn-images-1.medium.com/max/3840/0*QLvJ4Yg3Lc-vuwQz.jpg)
Web scraping is a technique where websites are downloaded to a local machine for various reasons. It is extremely useful to know due to its versatility and robust nature. A common application of web scraping is downloading files off of websites, and by using multi-threading you can significantly decrease the download time in some cases.
Let us cover some topics then apply them.
Materials required
You will need the following:
Python 3
An IDE or Text-editor
An internet connection
Access to a terminal (optional)
And most importantly, your brain! Just like most computer science projects, you should notice most of these materials are completely free or easily accessible: there is no excuse not to learn!
The Environment
I will be using Python 3. Because this is not a full-fledged Python tutorial, I am assuming you already know some basic programming.
I will also be using Atom with the atom-python-run plugin to write my code. However, anything that can write Python code will work, such as PyCharm or IDLE.

Web Scraping 101
It is important to know what is actually going on when you visit a website:
When you visit a URL, your computer sends a request to the web server of the website.
The server then responds with the files for the website.
Your browser then renders and displays the webpage.
](https://cdn-images-1.medium.com/max/2000/0*L3KYTATEKTBrmbZw.png)
What we are doing is not so different, we are just skipping step 3, or the rendering part.
Multi-threading 101
On a very basic level, a thread is a single process that executes a set of instructions. Multi-threading is the technique of creating multiple threads that run different processes, which can speed up tasks. The number and speed of threads depends on your processor, but having too many threads can sometimes hurt your performance. Multi-threading is sometimes used synonymously with parallel processing, but they are NOT the same.
](https://cdn-images-1.medium.com/max/2000/0*rdVO81ryLJETKIKS.png)
Important Modules
We are going to be using a couple packages, let us summarize each one:
requests
The backbone of this project, we will be using the requests module to send requests and download the webpage. We can fetch a website with the following command:
request = requests.get(URL) # replace URL with the URL of the website you want
BeautifulSoup
We will be using BeautifulSoup to parse and search through our downloaded webpage. Remember, it will be a large HTML document that we need to navigate through, which is exactly what this package handles for us. We can parse the webpage by doing the following:
page = requests.get(url).text # get the raw text of the request
soup = BeautifulSoup(page) # turn raw text into a BeautifulSoup object
# Example usage #
soup.find_all('p') # returns all p tags
This package is not built in Python, so we must install it using pip.
threading
We will be using this module to handle our multi-threaded downloads. We will not be doing anything too complicated, as all we have to do is specify the function in our method call:
processThread = threading.Thread(
target=functionHere, args=(arg1, arg2)) # parameters and functions have to be passed separately
processThread.start() # start the thread
The Steps
1. Identify the Problem
We will download past papers (end of year exams) from PapaCambridge. I chose this page as it has plenty of download links.

2. Research and inspection
Find out where and how the links are structured. The very first part of this step is finding your download link and inspecting the html. Right click and click inspect element on the download element.
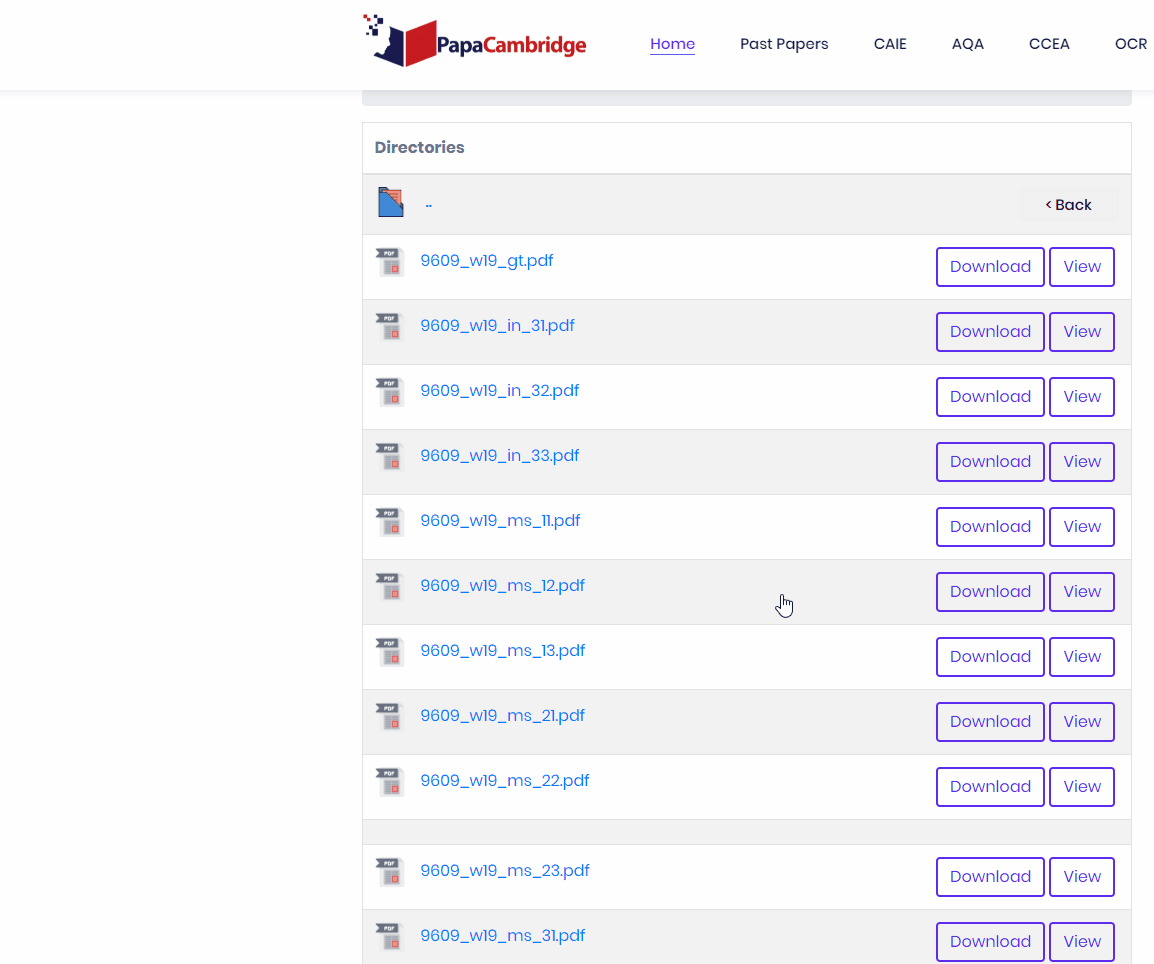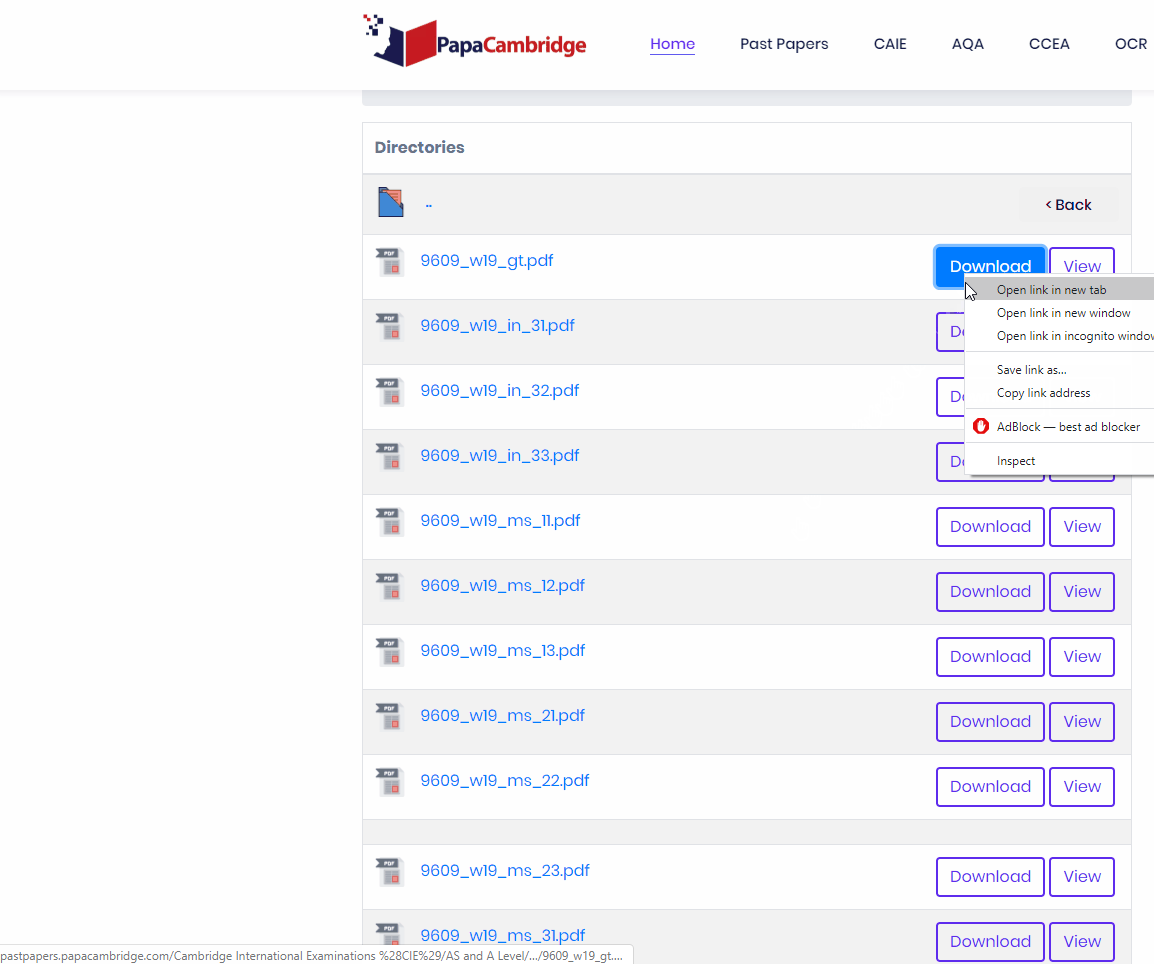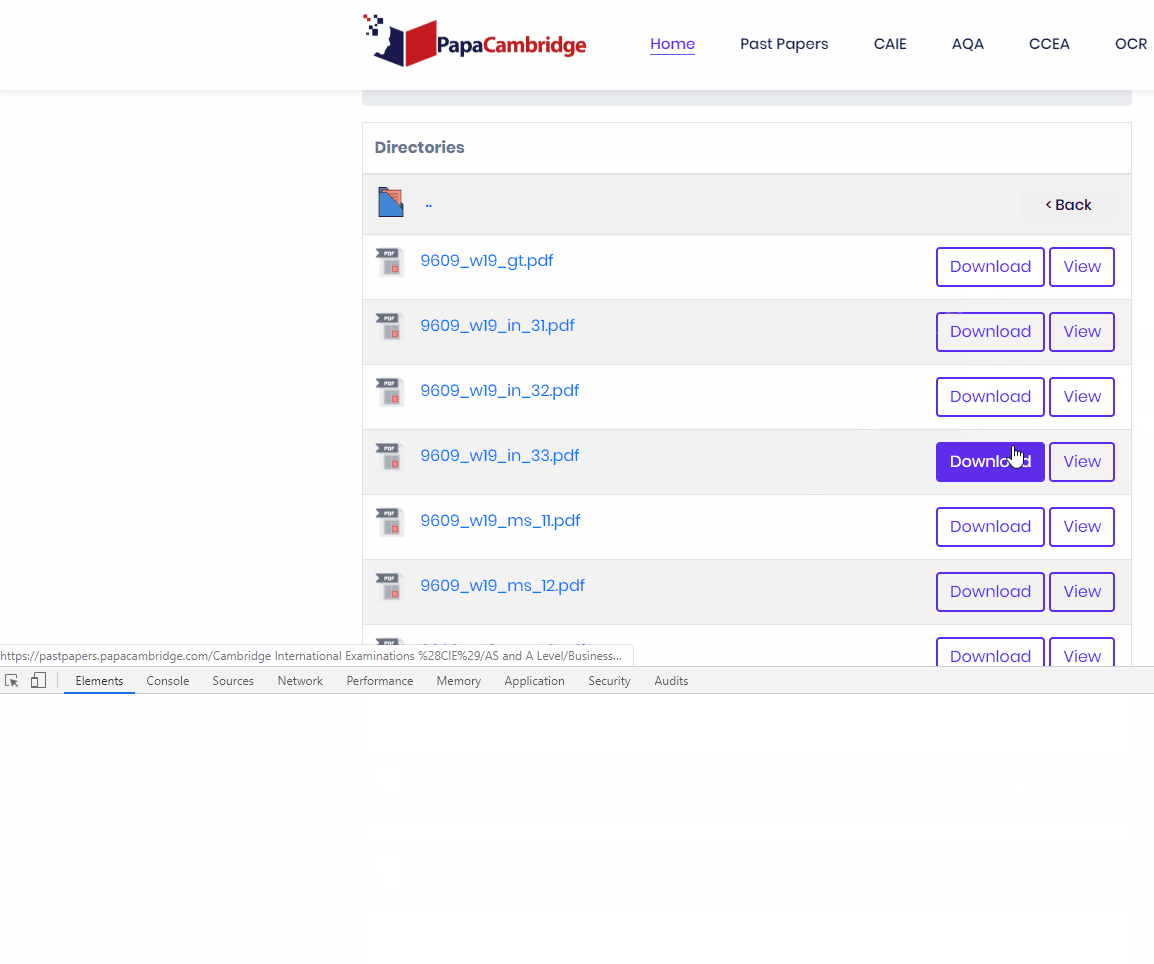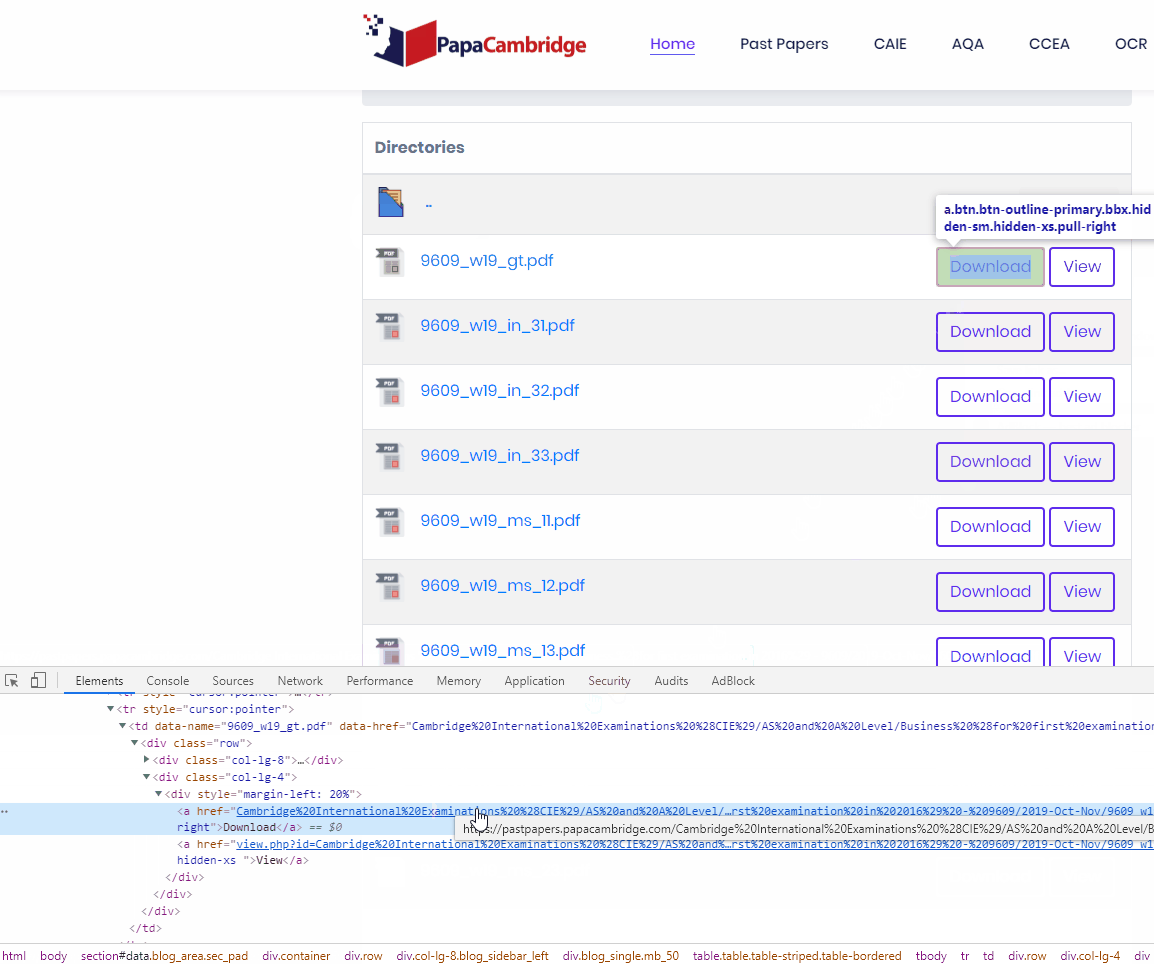
As you can see, we find the URL
Cambridge%20International%20Examinations%20%28CIE%29/AS%20and%20A%20Level/Business%20%28for%20first%20examination%20in%202016%29%20-%209609/2019-Oct-Nov/9609_w19_gt.pdf
But if you try visiting the URL, you will not reach a downloadable file. However, we can solve this problem by right clicking the download button and selecting Copy Link Address.

Aha! The real file is at:
[https://pastpapers.papacambridge.com/Cambridge%20International%20Examinations%20%28CIE%29/AS%20and%20A%20Level/Business%20%28for%20first%20examination%20in%202016%29%20-%209609/2019-Oct-Nov/9609_w19_gt.pdf](https://pastpapers.papacambridge.com/Cambridge%20International%20Examinations%20%28CIE%29/AS%20and%20A%20Level/Business%20%28for%20first%20examination%20in%202016%29%20-%209609/2019-Oct-Nov/9609_w19_gt.pdf)
Upon further inspection, it is the website’s base URL + the URL we found in the HTML! We now have everything we need to start our code.
3. Code
Let’s first install the BeautifulSoup module:
pip install beautifulsoup4
Now let us start our code. First our imports:
We have to fetch our webpage using the requests module:
Now let us find every URL on the page. We will make the tag has the text Download to ensure it is the correct link, and then append it to the site base URL. We will also create a list of all the download links.
Let us iterate through our download_urls array and download each link.
All together it should look like this:
Run the code and you will see it works! All the files are downloaded locally.
Adding Multi-threading
Now this is just one page of downloads, but let us say we wanted to download multiple pages.
As an example, let us concurrently download 4 pages at once.
1. [https://pastpapers.papacambridge.com/?dir=Cambridge%20International%20Examinations%20%28CIE%29/AS%20and%20A%20Level/Business%20%28for%20first%20examination%20in%202016%29%20-%209609/2019-May-June](https://pastpapers.papacambridge.com/?dir=Cambridge%20International%20Examinations%20%28CIE%29/AS%20and%20A%20Level/Business%20%28for%20first%20examination%20in%202016%29%20-%209609/2019-May-June)
2. [https://pastpapers.papacambridge.com/?dir=Cambridge%20International%20Examinations%20%28CIE%29/AS%20and%20A%20Level/Business%20%28for%20first%20examination%20in%202016%29%20-%209609/2018-Oct-Nov](https://pastpapers.papacambridge.com/?dir=Cambridge%20International%20Examinations%20%28CIE%29/AS%20and%20A%20Level/Business%20%28for%20first%20examination%20in%202016%29%20-%209609/2018-Oct-Nov)
3. [https://pastpapers.papacambridge.com/?dir=Cambridge%20International%20Examinations%20%28CIE%29/AS%20and%20A%20Level/Business%20%28for%20first%20examination%20in%202016%29%20-%209609/2018-May-June](https://pastpapers.papacambridge.com/?dir=Cambridge%20International%20Examinations%20%28CIE%29/AS%20and%20A%20Level/Business%20%28for%20first%20examination%20in%202016%29%20-%209609/2018-May-June)
4. [https://pastpapers.papacambridge.com/?dir=Cambridge%20International%20Examinations%20%28CIE%29/AS%20and%20A%20Level/Business%20%28for%20first%20examination%20in%202016%29%20-%209609/2018-March](https://pastpapers.papacambridge.com/?dir=Cambridge%20International%20Examinations%20%28CIE%29/AS%20and%20A%20Level/Business%20%28for%20first%20examination%20in%202016%29%20-%209609/2018-March)
First thing we should do is generalize our code. Let us add our new pages and change the URL variable to a parameter, and fit the code inside of a function. We will also import the os module to organize our files a bit better.
Pretty easy. Adding multi-threading will be super easy now because we made our code so specialized:
Final words
This code was for one specific example, but what makes someone a successful developer is their adaptability. With enough practice you can apply these web scraping techniques as well as others to any website, and become the master scraper. I know the above information was a lot, but with enough practice, anyone can master anything. I believe in you!